
2026년 2월, 데이터 주권법 시행령이 본격적으로 발효되면서 IT 업계와 개인 개발자들 사이에는 비상이 걸렸습니다. 더 이상 클라우드 기반의 AI 서비스에 무심코 데이터를 업로드했다가는 막대한 과태료 처분을 받거나, 회사의 기밀 정보가 국외로 유출되는 최악의 상황을 맞이할 수 있기 때문입니다. 이제 ‘나만의 AI’를 갖는 것은 단순한 기술적 호기심을 넘어, 데이터 주권을 지키기 위한 생존 전략이 되었습니다. 많은 분들이 개인 맞춤형 LLM(Large Language Model) 구축을 원하지만, 복잡한 보안 설정과 하드웨어 최적화 문제로 인해 망설이고 계실 겁니다. 오늘 이 글에서는 현직 AI 엔지니어가 실무에서 적용하는 데이터 유출 없는 온디바이스 AI 구축 노하우와 법적 리스크를 완벽하게 해소하는 기술적 보안 비책을 상세히 공개합니다.
데이터 주권법 위반인가? 클라우드 API 대신 로컬 LLM을 선택해야 하는 법적 이유
최근 발표된 2026 데이터 주권법 시행령의 핵심은 ‘국내 생성 데이터의 국외 이전 제한’과 ‘개인 민감 정보의 비식별화 의무’로 요약됩니다. 우리가 흔히 사용하는 글로벌 기업의 상용 API를 통해 데이터를 전송하는 행위 자체가 이제는 규제의 대상이 될 수 있다는 뜻입니다. 특히 의료, 금융, 법률 등 민감한 개인 정보를 다루는 프리랜서나 소규모 스타트업이라면, SaaS형 AI 모델 사용은 심각한 컴플라이언스 리스크를 안게 됩니다. 이러한 법적 제약 속에서 유일한 돌파구는 외부 서버와 통신하지 않는 완전한 폐쇄형 환경, 즉 **로컬 LLM(Local LLM)**을 구축하는 것입니다.
로컬 LLM은 인터넷 연결 없이도 작동하므로 데이터가 외부로 유출될 가능성을 원천 차단합니다. 이는 데이터 주권법이 요구하는 데이터 국지화(Data Localization) 요건을 자연스럽게 충족시킵니다. 과거에는 로컬 모델의 성능이 상용 모델에 비해 현저히 떨어졌지만, 2025년 하반기부터 공개된 Llama 4 계열의 경량화 모델과 Mistral의 파생 모델들은 매개변수(Parameter)가 적음에도 불구하고 놀라운 추론 능력을 보여주고 있습니다. 이제는 개인용 워크스테이션에서도 충분히 상용 모델에 버금가는 고성능 AI를 구동할 수 있는 시대가 열린 것입니다. 법적인 안전장치와 성능이라는 두 마리 토끼를 잡기 위해서는 로컬 환경으로의 전환이 선택이 아닌 필수가 되었습니다.
RTX 5090 vs NPU? 2026년 기준 개인용 AI 서버 구축을 위한 하드웨어 최적화 가이드
개인 맞춤형 LLM을 구축할 때 가장 큰 진입 장벽은 바로 하드웨어 리소스입니다. 많은 분들이 “최신 그래픽카드가 없으면 LLM을 못 돌리는 것 아니냐”고 걱정합니다. 하지만 2026년 현재, 하드웨어 트렌드는 양자화(Quantization) 기술의 고도화와 NPU(Neural Processing Unit)의 보편화로 인해 크게 변화했습니다. 굳이 수천만 원을 호가하는 엔터프라이즈급 GPU가 없더라도, 최적화된 설정만 거치면 일반 소비자용 하드웨어에서도 70B(700억 파라미터)급 모델을 구동할 수 있습니다.
가장 효율적인 전략은 4비트 혹은 그 이하로 모델을 압축하는 양자화 기술을 적극 활용하는 것입니다. 예를 들어, FP16(16비트 부동소수점) 원본 모델은 막대한 VRAM을 요구하지만, 이를 GGUF 포맷의 4비트(Q4_K_M)로 변환하면 VRAM 사용량을 획기적으로 줄이면서도 성능 저하는 인간이 체감하기 힘든 수준인 3% 내외로 방어할 수 있습니다. 엔지니어 관점에서 추천하는 2026년 가성비 세팅은 VRAM 24GB 이상을 지원하는 RTX 4090/5090급 GPU 한 장 혹은 Mac Studio와 같이 통합 메모리 구조를 가진 시스템을 활용하는 것입니다. 특히 애플 실리콘의 경우, 통합 메모리를 통해 시스템 RAM을 GPU 메모리처럼 쓸 수 있어 가성비 면에서 개인용 AI 서버의 최적의 대안으로 떠오르고 있습니다.
또한, 최근 출시된 AI 전용 PC들은 CPU 내장 NPU 성능이 대폭 향상되어, 7B~13B 수준의 경량 모델(SLM)은 GPU 없이도 쾌적하게 구동 가능합니다. 따라서 무조건 고가의 장비를 구매하기보다는, 내가 구동하려는 모델의 크기와 목적(단순 챗봇 vs 복잡한 추론)에 맞춰 하드웨어를 선택하는 것이 비용 효율적인 최적화의 첫걸음입니다.
RAG(검색 증강 생성) 아키텍처 적용 시 개인정보 유출을 막는 엔지니어링 비법
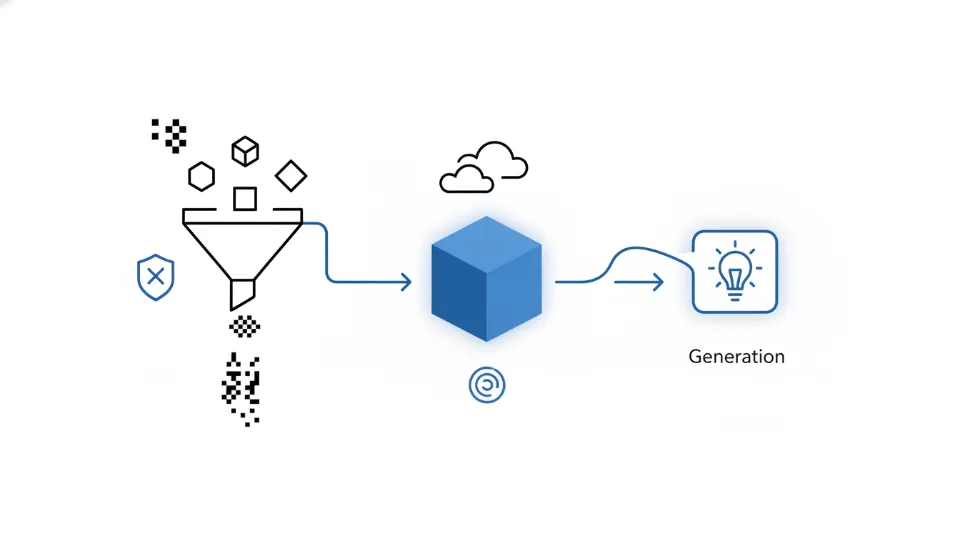
개인 맞춤형 LLM의 꽃은 바로 내가 가진 데이터(PDF, 문서, 노트 등)를 AI가 학습하지 않고도 참고하여 답변하게 만드는 RAG(Retrieval-Augmented Generation) 기술입니다. 하지만 이 과정에서 치명적인 보안 허점이 발생할 수 있습니다. 사용자의 개인 문서가 벡터 데이터베이스(Vector DB)로 변환되는 과정에서 주민등록번호, 전화번호, 계좌번호 등의 민감 정보(PII)가 평문 그대로 저장될 위험이 있기 때문입니다. 이는 데이터 주권법 시행령 위반의 직접적인 원인이 됩니다.
이를 방지하기 위해 현업 엔지니어들은 PII 마스킹(Masking) 및 익명화 전처리 파이프라인을 반드시 구축합니다. 문서를 청크(Chunk) 단위로 쪼개기 전에, 정규표현식(Regex)이나 경량화된 PII 탐지 모델(Presidio, GlanER 등)을 통과시켜 민감 정보를 ‘
또한, 벡터 DB 자체를 클라우드(Pinecone 등)가 아닌 로컬 인스턴스(ChromaDB, Weaviate Local)로 구축하는 것이 중요합니다. 로컬 컨테이너 환경에서 Docker를 활용해 DB를 띄우고, 외부 포트 접근을 차단한 채 오직 내부 네트워크(localhost)에서만 LLM과 통신하도록 설정하십시오. 이러한 샌드박스(Sandbox) 구조는 2026년 보안 감사 기준에서도 가장 권장하는 아키텍처입니다. 보안은 불편한 것이 아니라, 나의 AI 비서를 오랫동안 안전하게 사용하기 위한 가장 강력한 기반 시설임을 명심해야 합니다.
미세 조정(Fine-tuning) 없이 프롬프트 엔지니어링만으로 법적 리스크 최소화하기

많은 분들이 자신의 스타일을 모방하는 AI를 만들기 위해 성급하게 파인 튜닝(Fine-tuning)을 시도하려 합니다. 하지만 모델 자체를 추가 학습시키는 파인 튜닝은 원본 모델의 가중치(Weight)를 변경하므로, 이 과정에서 학습 데이터에 포함된 저작권 문제나 개인정보가 모델 안에 영구적으로 ‘기억’되는 데이터 오염(Data Poisoning) 문제를 야기할 수 있습니다. 한번 모델 내부에 각인된 정보는 제거하기가 매우 까다롭기 때문에, 2026년의 강화된 법규 아래에서는 매우 신중해야 하는 접근 방식입니다.
이에 대한 대안으로 시스템 프롬프트(System Prompt) 최적화와 인컨텍스트 러닝(In-Context Learning)을 강력히 추천합니다. 모델을 직접 건드리는 대신, 프롬프트의 최상단에 “당신은 철저한 보안 규정을 준수하는 법률 자문 AI입니다. 모든 답변은 제공된 컨텍스트 내에서만 생성해야 하며, 외부의 불확실한 정보를 사실인 것처럼 말해서는 안 됩니다.”와 같은 메타 지침(Meta-Instruction)을 강력하게 주입하는 것입니다. 이는 모델의 수정 없이도 답변의 톤앤매너를 조절할 수 있는 가장 안전하고 효율적인 방법입니다.
특히 최신 LLM들은 컨텍스트 윈도우(Context Window)가 128k, 1M 토큰 이상으로 매우 커졌기 때문에, 수십 장의 매뉴얼을 프롬프트에 통째로 넣어도 문맥을 완벽하게 이해합니다. 굳이 위험 부담과 비용이 큰 파인 튜닝을 고집할 이유가 사라진 셈입니다. 프롬프트 엔지니어링이야말로 법적 규제를 유연하게 피해 가면서도 개인 맞춤형 AI의 성능을 극대화할 수 있는, 현직 엔지니어들이 가장 선호하는 ‘가성비’ 전략입니다.
자주 묻는 질문 (FAQ)
Q. 개인이 취미로 만든 LLM도 2026 데이터 주권법의 처벌 대상이 되나요?
원칙적으로 영리 목적이 없는 개인의 단순 학습용 모델은 처벌 대상에서 제외될 가능성이 큽니다. 하지만 해당 모델이 타인의 개인정보를 포함한 데이터를 학습했거나, 웹상에 공개되어 제3자가 접근 가능한 상태라면 ‘개인정보 보호법’ 위반 소지가 있습니다. 따라서 로컬 환경에서 폐쇄적으로 운영하는 것을 강력히 권장합니다.
Q. 맥북(MacBook)으로도 고성능 개인용 LLM 구동이 가능한가요?
네, 가능합니다. 애플 실리콘(M3, M4 칩셋 등)이 탑재된 맥북은 통합 메모리 구조 덕분에 고가의 외장 GPU 없이도 램 용량(32GB 이상 권장)만 넉넉하다면 70B급 양자화 모델을 쾌적하게 구동할 수 있어 개발자들 사이에서 인기가 높습니다.
Q. RAG 구축 시 어떤 벡터 DB를 사용하는 것이 가장 안전한가요?
데이터 주권과 보안을 최우선으로 한다면 클라우드 기반 서비스(SaaS)보다는 ChromaDB, Weaviate, Qdrant 등의 오픈소스 벡터 DB를 Docker 컨테이너를 통해 로컬 서버(On-premise)에 직접 설치하여 외부 네트워크와 차단된 상태로 운영하는 것이 가장 안전합니다.